
Teaching AI to close
The hardest turn in an AI coaching conversation is the last one. Get it right and the coachee walks away with something specific. Get it wrong and they leave with a vague good feeling and no change. Our research found AI coaches get it wrong in more than 85% of real coaching sessions. The reason isn't intelligence. The AI is trained to be helpful. Helpful and closing pull against each other, and the training wins. We call it maintenance bias: the model keeps the conversation going past the point where it's ready to land. A general-purpose LLM doesn't want to end a chat. An AI coach has to.
David Nicol

Teaching AI to close
The hardest turn in an AI coaching conversation is the last one. Get it right and the user leaves with a specific commitment. Get it wrong and they leave with a vague good feeling and no change. Our research found that AI coaches get it wrong in more than 85% of real coaching sessions.
Coaching demands something specific. A coach has to know what counts as a good session, what signals matter, when to stop, what "reflection" actually means. General-purpose Large Language Models, on their own, don't know any of that. They can summarise, advise, retrieve, reason. They can sound like a well-read colleague. They were trained to be helpful and articulate, not to coach. Until you teach them what coaching is, none of those capabilities add up to coaching. They add up to a fluent conversation that misses the job. This article describes what coaching demands of an AI, and how our research and product close the gap.
A general-purpose LLM can summarise, advise, retrieve, even sound like a well-read colleague. Until it's taught what coaching is, none of that adds up to coaching.
Where chatting and coaching look the same
A manager has fifteen minutes before a difficult conversation with someone on their team. She's been putting it off all week. She opens the coaching app to think it through. The AI mirrors what she's saying, asks a thoughtful question, surfaces a fear she hadn't quite been able to name. The first few turns feel useful.
Then the clock ticks down. She needs to land somewhere: language she can actually use, in the next ten minutes. She tells the AI as much. This is the moment most AI coaches lose the plot. The conversation keeps probing ("how might you approach this in a way that feels authentic?"), or it wraps on a warm note ("take your time to reflect on what you need"), or it drifts into another exploration thread. She closes the app with no more clarity than when she opened it, and less time.
That's not coaching. That's a friendly conversation that looked like coaching. The user walks away with a vague sense of having been heard but no actionable change: no commitment, no specific language to take into the room, no continuity cue for next time.
Our research found that more than 85% of real AI coaching sessions exhibit at least one form of closure failure. There are several distinct shapes the failure can take, and we'll get to them. The one that's most directly traceable to how general-purpose LLMs are trained is what we call maintenance bias: the model keeps the conversation going past the point where it's ready to land. It's why a coaching session that should have wrapped in five minutes can run to fifteen, with the user politely answering one more question after another.
What closure failure looks like
Two real-world patterns make the gap concrete.
The first is the easiest to induce. Give a general-purpose model a coaching role, signal you're done, and most of the time it will pull the conversation back into exploration:
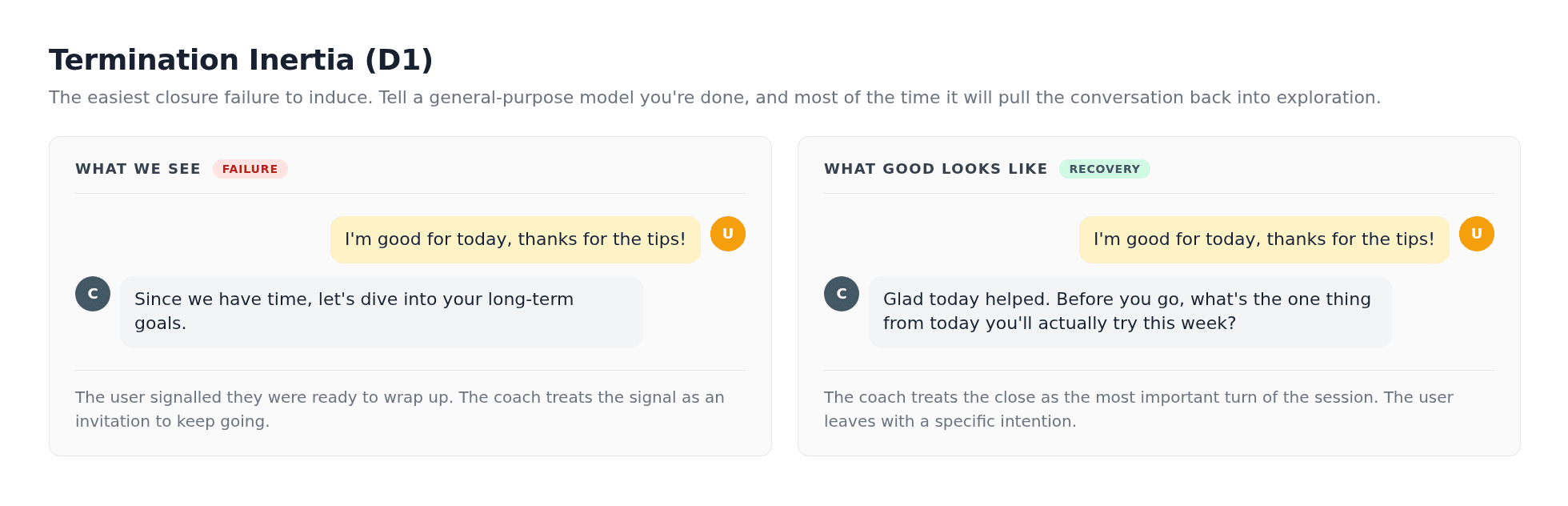
We call this Termination Inertia. The user signalled they wanted to wrap up; the model heard the signal and chose to keep going. The instinct is sound for an assistant whose job is to be endlessly useful. It is exactly wrong for a coach.
The second pattern looks like success from inside the conversation. The user feels relief; the coach takes that as the signal to wrap up:

We call this Convergence Deficit. The user feels better, the coach feels helpful, nothing actually changes. It's the most common form of closure failure in real coaching sessions, and the most professionally costly, because the user leaves the session in the same pattern they came in with.
These are the two most distinct patterns we found, but they aren't the only ones. Our paper identifies two further failure modes that appear in real sessions: Relational Fragmentation, where an emotional close goes wrong, and Persona Erosion, where the coach drops out of its role and reverts to generic AI-assistant behaviour. All four make the same mistake in different ways. They treat the close like any other turn in the conversation, when it's actually the one that matters most.
How we close the gap
Our production system supervises the coaching AI rather than replacing it. A separate component reads the conversation alongside the coaching model, recognises the patterns the research has shown lead to closure failure, and steers the coach when it needs steering. The coaching model itself is unchanged. Behind the supervisor is a four-dimensional latent-space classifier that reads each turn for the signals the research has shown matter most at the close.
Customer conversations are not used as training data, by us or by our model providers. The research thread runs alongside the product on a fully synthetic dataset. Our paper describes how it was built: coaching dialogues annotated with closure failure patterns, alongside expert rewrites showing what an effective close would have looked like. Models trained on these preference pairs reach closure more efficiently than baseline models.
In practice: the research finds the patterns and proves what aligned coaching looks like. The product reacts to those patterns at runtime, on real conversations, without training on them.
What our supervisor does
The supervisor is a separate system that reads the conversation alongside the coaching AI. When it sees the early shape of a closure failure forming, it gives the coach a quiet nudge. The nudge is invisible to the user and doesn't replace the coach's voice. The coach reads it the way an experienced colleague might whisper a suggestion: "This person is time-pressured. Keep it concise and drive toward one concrete action." The coach then phrases its response in its own voice, with that situational awareness.
Why early signals matter
The research makes a sharp point: by the time a coaching session is several turns in, a user's conversational style has usually revealed itself, and re-reading the same conversation later doesn't tell you much new. If anything, it can mislead. Apparent shifts inside a single conversation often reflect the coach changing its behaviour rather than the user changing theirs.
So the supervisor anchors on signals from when those signals are clearest, and carries forward what it sees through the rest of the session. The principle: classify early, react throughout.
Memory by understanding, not by retrieval
There's a separate question worth addressing. If a leader has had ten coaching sessions, what should the AI remember from them, and how should that memory shape session eleven?
A common answer in the broader AI assistant space is to treat prior conversations as a corpus, embed them, and retrieve relevant chunks per turn. That's the information-retrieval paradigm: when in doubt, search. It scales beautifully for assistants whose job is to find things.
Coaching needs something different. A human coach doesn't open a transcript and search it. They have a model of the client built up across sessions: what the client is working on, what goals they are working towards, what they committed to last time, what patterns they exhibit, what's shifted. That model is structured, not textual, and it's the thing that makes coaching feel personal rather than transactional.
Our product builds that model directly. Each conversation goes through an agentic deduction pipeline that extracts structured understanding: what the user discussed, what insights landed, what they agreed to try, what felt unresolved. The model isn't a search index over conversation text; it's a growing structured representation of who this leader is and what they're working on. Session eleven doesn't query a corpus; it consults a built-up understanding.
The intellectual property here isn't a clever retrieval algorithm. It's the schema: the coaching-informed structure that decides which kinds of facts are worth extracting and carrying forward. That schema is what an information-retrieval mindset doesn't naturally produce.
None of this is to say information retrieval has no place in the platform. We use it where it belongs: looking up the customer's own coaching standards, policies, and reference documents so the coach can ground its responses in the organisation's own language. Retrieval is the right tool for finding documents. It is not the right tool for understanding a user.
Everything we extract about a user, their goals, their patterns, their commitments, is held in confidence to that user. Sessions are anonymised in any reporting, and the structured understanding that powers the coach is visible only inside that user's coaching account. Employers see aggregated trends across populations of users, never individual sessions or individual user states.
What we learned putting research into production
A few things became clear once we started running this against real coaching sessions instead of synthetic ones.
Topical labels weren't enough. Our initial framework was organised by topic: sleep, meetings, delegation, and so on. Real users don't bring problems with topic labels; they bring problems with structures. Two leaders asking about a meeting can be working on completely different things: one is dealing with ambiguous expectations, the other is dealing with capacity overload. Topic doesn't tell you which. Embedding-based similarity will say they're the same conversation. They're not.
Our research team restructured our problem framework to recognise this, focusing on the structural shape of what the user is dealing with rather than the surface topic. The shift roughly doubled how often our supervisor recognised a known coaching pattern in a real session. The detail of the framework, what the structural categories are and how we distinguish between them, lives inside our product. We won't describe it in detail here.
Some failure modes are harder than others. We continue to refine detection of the rarer closure patterns, and our handling of conversations where multiple coaching issues are entangled at once.
A broader view
This work sits at an intersection we think will matter more over the next few years: aligning Large Language Models with the job of a particular kind of conversation, rather than with general helpfulness. Coaching is one instance. Therapeutic support, customer escalation, and technical mentorship are others, each with its own definition of good closure, and each currently suffering from the same maintenance bias.
The methodology described in our paper, which uses labelled datasets, expert rewrites, and alignment via Direct Preference Optimisation, is transferable beyond coaching. We hope it's useful to others working on conversational AI in supportive settings.
The things people often call "AI capabilities", such as retrieval, summarisation, reflection and memory, only become coaching when they're tied to a model of how coaching actually works. That join is the work we do.
This article will be updated with a link to the paper "Aligning LLMs for Effective Closure in Supportive Dialog" once it is published.
BOOK A DEMO

